
Document structure is implicitly conveyed in audio renderings by using audio layout made up of extra-textual speech and non-speech audio cues. The following subsections describe this audio layout and outline the rules for producing such renderings from the internal representation described in Section 2.1.
Audio cues are either fleeting or persistent. This classification is orthogonal to the earlier classification into speech and non-speech audio cues. We define terms fleeting and persistent below:
A cue that does not last. Such cues are characterized by their duration being specified by the nature of the cue itself.
A cue that lasts, i.e., persists. The duration for such cues is specified by other ongoing events in the audio rendering, rather than by the cue itself.
The following paragraphs clarify the above definitions by giving some examples of fleeting and persistent cues.
AS TE R minimizes the use of extra-textual announcements by cueing document structure implicitly wherever possible. Fleeting sound cues are associated with objects like paragraphs and bulletted lists to convey structure efficiently. To give a visual analogy, we all know what a table of numbers or a centered paragraph look like, but what do they “sound” like? Associating sound cues (earcons [BGB88]) with specific structures takes a step towards answering this question.
Fleeting cues are typically used to introduce particular objects. However, more than an introductory cue is needed when rendering complex structures. For instance, a fleeting cue at the beginning of each item is not sufficient when rendering an itemized list —the listener is likely to forget the current context if the items are complex.
In the visual setting, the logical structure of a list is displayed by super-imposing indentation, an implicit layout cue, on the text. AS TE R uses persistent audio cues to achieve a similar effect. These cues consist of either a change in some characteristic of the speaking voice or a sound that repeats in the background and have the advantage of being present during the entire rendering, without detracting from the flow of information.
Audio layout Audio layout is achieved by super-imposing fleeting and persistent cues on the rendering. To convey nesting effectively, the AFL state changes used to achieve persistent cues need to be monotonic in the mathematical sense. Let P represent a point in audio space. Let f be a change-of-state function. To convey nesting effectively, f should be monotonic —there should exist an ordering
|
| (4.1) |
where this ordering is perceptible. This is where we exploit the abstraction of a speech space and the operators it provides. For instance, the following AFL statement can be used to define a function that generates new AFL states for rendering itemized lists:
(afl:step-by afl:⋆current-speech-state⋆ 'afl:average-pitch 1)
This notion of monotonicity in change of AFL states will be exploited once again in Section 4.3 when designing an audio notation for mathematics.
The rendering rule for different sectioning levels uses a fleeting speech cue by announcing the current level, e.g., “section”, announcing positional information, e.g., section number, and then speaking the title of the sectional unit. A persistent sound cues the title —it is “highlighted” by playing a sound in the background. Here is the corresponding rendering rule:
(def-reading-rule (section default)
"Render section"
(afl:new-block
(afl:local-set-state
(afl:step-by afl:⋆current-speech-state⋆
'afl:smoothness 2))
(read-aloud (section-name section))
(read-aloud (section-number section)))
(afl:new-block
(afl:local-set-state
(afl:step-by afl:⋆current-speech-state⋆
'afl:head-size 1))
(afl:local-set-state
(afl:select-sound afl:⋆current-audio-state⋆
⋆title-highlight⋆))
(afl:local-set-state
(afl:switch-on afl:⋆current-audio-state⋆))
(read-aloud (section-title section)))
...);render body of section
Paragraphs are introduced by a fleeting sound:
(def-reading-rule (paragraph default)
(afl:new-block
(afl:synchronize-and-play ⋆paragraph-cue⋆)
(afl:paragraph-begin) ;rising intonation.
<render contents>))
Lists, centered text and other structures are marked up in LATEX as special environments and are characterized by their visual layout. Thus, a list of items is cued by indenting the items in the list. Nested lists are displayed by indenting them with respect to the outer list —in audio, we use change of pitch.
An itemized list is represented internally as an object of type itemized-list, with the list of items as its children. Each item itself can be a complex object. Here is the AFL rule for rendering object itemized-list.
(def-reading-rule (itemized-list default)
(afl:new-block
(afl:local-set-state
(afl:step-by afl:⋆current-speech-state⋆
'afl:average-pitch 1))
(loop for child in children do (read-aloud child))))
This rendering rule begins a block, locally sets the state of the audio formatter by raising the pitch of the voice, and then renders the contents of the itemized list. These contents are rendered relative to the containing list. When this rule is applied to a nested list, the inner list gets rendered relative to the outer list —the pitch goes up by one step when rendering the outer list, and goes up by another step when rendering the inner list. Thus, the local scope introduced by the AFL block works effectively in conveying nested structures.
Just speaking the contents of a table does not convey the relation between its entries. Saying
“next column” and “next row” before rendering each new row or column is too distracting.
We overcome this problem by exploiting stereo (spatial audio). The first element of each row
is spoken solely on the left speaker; the rendering then progressively moves to the right, with
the last element spoken solely on the right speaker. Thus, given a row (Ak0,Ak1,…,Akn),
element Aki is spoken with the volume of the left speaker at  max-volume and the right
volume at
max-volume and the right
volume at 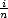 max-volume.
max-volume.
We achieve this with a simple AFL rendering rule: the volume of the left and right speakers are dimensions in audio space, and implementing the above rendering only requires moving along the line spanned by these dimensions.